
##예외 처리
###예외의 개념
예외(Exception) 은 일종의 오류로 두 가지로 나눌 수 있다.
- 문법 오류 : 오타와 같이 자바 구문에 어긋난 코드 때문에 발생하고, 컴파일시에 발생하는 오류
- 실행 오류 : 프로그램 실행시 상황에 따라 발생하는 오류
실행 오류에는 프로그램 자체의 구조적인 문제로 인한 논리적 오류와 자바 가상 머신 자체의 문제로 인한 오류 그리고 예외가 있다. 논리 오류는 논리적 모순이 생기지 않도록 코딩하는 수밖에 없으며, 자바 가상 머신 자체의 오류는 프로그래머가 책임질 수 있는 수준의 오류가 아니다.
예외(Exception)은 프로그램 실행 중에 발생할 수 있는 예기치 않은 사건으로 프로그래머의 노력으로 처리할 수 있다.
자바 가상 머신은 프로그램 실행중에 예외가 발생하면 관련된 예외 클래스로부터 예외 객체를 생성하여 프로그램에서 지정된 예외 처리 구문으로 넘긴다. 프로그램에 지정된 예외 처리 구문은 예외가 발생하면 자바 가상 머신에 의해 호출되고 예외 객체를 자바 가상 머신으로부터 넘겨받아 적절한 처리를 수행한다.
###try ~ catch
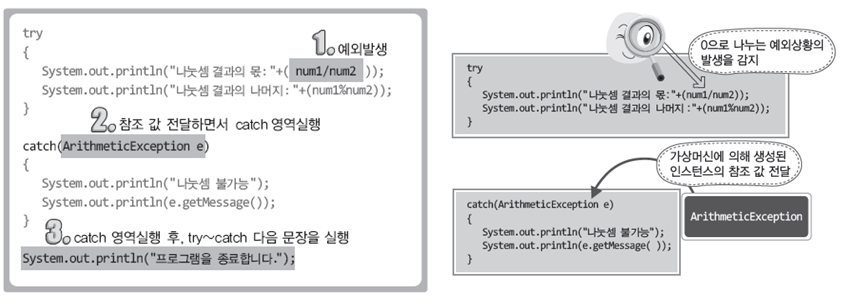
try 블록은 예외가 발생할 가능성이 있는 범위를 지정하는 블록이다. try 블록은 최소한 하나의 catch 블록이 있어야 하며, catch 블록은 try 블록 다음에 위치한다.
catch 블록의 매개변수는 예외 객체가 발생했을 때 참조하는 변수명으로 반드시 java.lang.Throwable 클래스의 하위 클래스 타입으로 선언되어야 한다.
지정된 타입의 예외 객체가 발생하면 try 블록의 나머지 문장들은 수행되지 않고, 자바 가상 머신은 발생한 예외 객체를 발생시키며 발생한 예외 객체 타입이 동일한 catch 블록을 수행한다.
finally 블록은 필수 블록은 아니다.
finally 블록이 사용되면 finally 블록의 내용은 예외 발생 유무나 예외 catch 유무와 상관 없이 무조건 수행된다. 따라서, 데이터베이스나 파일을 사용한 후 닫는 기능과 같이 항상 수행해야 할 필요가 있는 경우에 사용한다.
try{
예외 발생 가능성이 있는 문장들;
}catch(예외 타입1 매개변수명){
예외타입1의 예외가 발생할 경우 처리 문장들;
}catch(예외 타입 n 매개변수명){
예외타입 n의 예외가 발생할 경우 처리 문장들;
}finally{
항상 수행할 필요가 있는 문장들;
}
###throw & throws
자바의 예외 처리 방법은 예외가 발생한 지점에서 try-catch 또는 try-catch-finally 블록을 이용하여 직접 처리하지 않아도 예외가 발생한 메소드를 호출한 지점으로 예외를 전달하여 처리하는 방법이 있다.
이때 사용하는 예약어가 throws 이다.
기존의 예외 클래스로 예외를 처리할 수 없다면 사용자만의 예외 클래스를 작성하여 발생시킬 수 있다. 사용자가 예외 클래스를 정의하려면 예외 클래스의 최상위 클래스인 java.lang.Exception 클래스를 상속받아 클래스를 정의한다.
class 예외 클래스 이름 extends Exception
자바 가상 머신은 프로그램 수행중에 예외가 발생하면 자동으로 해당하는 예외 객체를 발생시킨 다음 catch 블록을 수행한다.
하지만 예외는 사용자가 강제적으로 발생시킬 수도 있다. 자바는 예외를 발생시키기 위해 throw 예약어를 사용한다.
throw new 예외 클래스 이름(매개변수);
throw 를 이용한 예외 발생시에도 try-catch-finally 구문을 이용한 예외 처리를 하거나, throws 를 이용하여 예외가 발생한 메소드를 호출한 다른 메소드로 넘기는 예외 처리 방법을 사용해야 한다.
class AgeException extends Exception{
AgeException(){
super("나이가 음수가 될 수는 없다");
}
}
public class UserException {
public static void main(String[] args) {
int age = -2;
try{
readAge(age);
}catch(AgeException e){
e.printStackTrace();
}
}
public static void readAge(int age) throws AgeException{
if(age < 0){
throw new AgeException();
}
}
}
Exception을 상속받는AgeException이라는 사용자 정의 예외를 만들었다.- main이 실행되면 음수를 매개변수로 갖는
readAge함수를 호출한다. - readAge 함수는 age가 음수이기 때문에
new로AgeException을 생성한 후 readAge를 호출한 main으로 던진다. AgeException을 받은 main 함수는 catch에서 예외를 받아서 메시지를 출력한다.
##자바의 메모리 모델
운영체제가 JVM을 포함해서 모든 응용 프로그램에게 동일한 크기의 메모리 공간을 할당할 수 있는 이유는 가상 메모리 기술에서 찾을 수 있다. JVM은 운영체제로부터 할당 받은 메모리 공간을 기반으로 자바 프로그램을 실행해야 하며, 할당 받은 메모리 공간을 이용해서 자기 자신도 실행하고, 자바 프로그램도 실행을 한다.
JVM의 메모리 구분 및 관리 기준
- 메소드 영역 - 메소드의 바이트코드, static 변수
- 스택 영역 - 지역변수, 매개변수
- 힙영역 - 인스턴스
###메소드 영역
- 자바 바이트코드 : 자바 가상머신에 의해서 실행되는 코드
- 메소드의 자바 바이트코드는 JVM이 구분하는 메모리 공간 중에서 메소드 영역에 저장된다.
- static으로 선언된 클래스 변수도 메소드 영역에 저장된다.
- 클래스의 정보가 JVM의 메모리 공간에 LOAD 될 때 할당 및 초기화 되는 대상은 메소드 영역에 할당된다.
###스택 영역
- 매개변수, 지역변수가 할당되는 메모리 공간
- 프로그램이 실행되는 도중에 임시로 할당되었다가 바로 이어서 소멸되는 특징이 있는 변수가 할당된다.
- 메소드의 실행을 위한 메모리 공간으로도 정의할 수 있다.
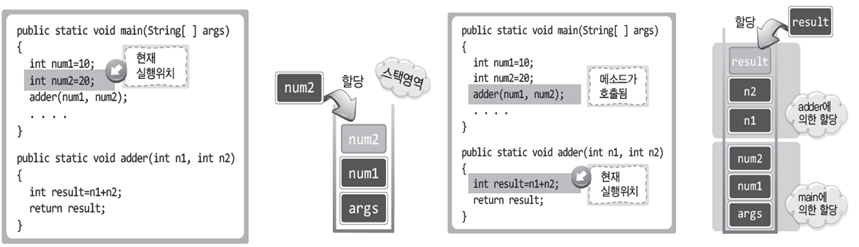
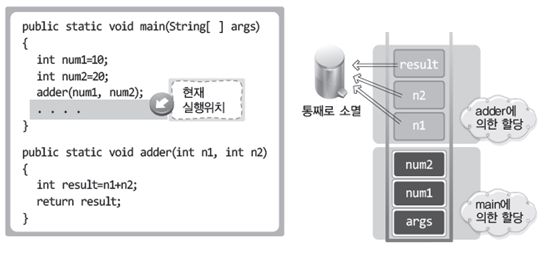
스택에 할당된 지역변수는 해당 메소드를 빠져 나가면 소멸된다.
###힙 영역
- 인스턴스가 생성되는 메모리 공간
- JVM에 의한 메모리 공간의 정리(Garbage Collection)가 이뤄지는 공간
- 할당은 프로그래머가. 소멸은 JVM이 한다.
- 참조 변수에 의한 참조가 전혀 이뤄지지 않는 인스턴스가 소멸의 대상이 된다. 따라서 JVM은 인스턴스의 참조관계를 확인하고 소멸 할 대상을 선정한다.
##Object 클래스
모든 클래스는 Object 클래스를 상속한다. 자바 클래스가 아무것도 상속하지 않으면 java.lang 패키지의 Object 클래스를 자동으로 상속한다. 때문에 모든 자바 클래스는 Object 클래스를 직접 혹은 간접적으로 상속하므로 다음 두가지가 가능하다.
- 자바의 모든 인스턴스는 Object 클래스의 참조변수로 참조 가능
- 자바의 모든 인스턴스를 대상으로 Object 클래스에 정의된 메소드 호출 가능
###finalize
finalize 메소드는 인스턴스가 완전히 소멸되기 직전 호출되는 메소드이다.
protected void finalize() throws Throwable{
super.finalize();
System.out.println("finalize");
}
위 코드처럼 api에 있는 메소드를 오버라이딩 할 경우 대상 메소드에 대한 정보가 부족하기 때문에 오버라이딩된 메소드도 호출이 되도록 오버라이딩을 해야된다.
그래서 super.finalize() 를 작성해주는 것이다.
GC는 한번도 발생하지 않을 수 있으며, GC가 발생하면 소멸의 대상이 되는 인스턴스는 결정되지만 이것이 실제 소멸로 바로 이어지지는 않는다.
따라서 finalize 메소드가 반드시 호출되기 원한다면 아래 코드를 추가로 삽입해야 한다.
System.gc(); //가비지 컬렉션을 명령함
System.System.runFinalization(); //GC에 의해서 소멸이 결정된 인스턴스를 즉시 소멸하라
###equals
equals 메소드는 인스턴스간의 내용을 비교하여 boolean 값을 반환한다. equals 와 == 는 어떠한 차이점이 있을까?
equals 는 메소드 이며 객체끼리 내용을 비교할 수 있고 == 는 비교를 위한 연산자 이다.
equals 메소드는 비교하고자 하는 내용 자체를 비교 하지만 == 연산자는 비교하고자 하는 대상의 주소값을 비교 한다.
String 객체를 비교시에는 equals를 사용하자
###clone
##Generics
제네릭스는, JDK1.5에서의 가장 큰 변화 중의 하나로, 다양한 타입의 객체들을 다루는 메서드나 컬렉션 클래스에 컴파일 시의 타입 체크(compile-time type check)를 해주는 기능이다. 객체의 타입을 컴파일 시에 체크하기 때문에 객체의 타입 안정성을 높이고 형변환의 번거로움이 줄어든다. ArrayList와 같은 컬렉션 클래스는 다양한 종류의 객체를 담을 수 있긴 하지만 보통 한 종류의 객체를 담는 경우가 더 많다. 그런데도 꺼낼 때 마다 타입체크를 하고 형변환을 하는 것은 아무래도 불편할 수밖에 없다.
- 타입 안정성을 제공한다.
- 타입체크와 형변환을 생략할 수 있으므로 코드가 간결해 진다.
타입 안정성을 높인다는 것은 의도하지 않은 타입의 객체를 저장하는 것을 막고, 저장된 객체를 꺼내올 때 원래의 타입과 다른 타입으로 형변환되어 발생할 수 있는 오류를 줄여준 다는 뜻이다.
간단히 얘기하면 다룰 객체의 타입을 미리 명시해줌으로써 형변환을 하지 않아도 되게 하는 것이다. 그게 전부이다. 너무 어렵게 생각하지 않길 바란다.
제네릭스에서는 참조형 타입(reference type), 간단히 말해서 ‘타입(type)’을 의미하는 기호로 ‘T’를 사용한다. ’T‘는 영단어 ‘type’의 첫 글자로, 어떠한 참조형 타입도 가능하다는 것을 의미한다. ‘T’뿐 만아니라 때때로 요소(element)를 의미하는 ‘E’, 키(key)를 의미하는 ‘K’, 값(value)을 의미하는 ’V’도 사용된다. 이들은 기호의 종류만 다를 뿐 ‘임의의 참조형 타입’을 의미한다는 것은 모두 같다. 마치 수학식 ‘f(x, y) = x + y’가 ‘f(k, v) = k + v’와 다르지 않은 것처럼 말이다. 기존에는 다양한 종류의 타입을 다루는 메서드의 매개변수나 리턴타입으로 Object타입의 참조변수를 많이 사용했고, 그로 인해 형변환이 불가피했지만, 이젠 Object타입 대신 원하는 타입을 지정하기만 하면 되는 것이다.
class FruitBox{
Object item;
public void store(Object item){
this.item = item;
}
public Object pullout(){
return item;
}
}
//Generic Class example
class FruitBox<T>{ //T라는 이름이 매개변수화 된 자료형임을 나타냄
T item;
public void store(T item){
this.item = item;
}
public T pullout(){
return item;
}
}
//T에 해당하는 자료형의 이름은 인스턴스를 생성하는 순간에 결정이 된다.
FruitBox<Orange> abox = new FruitBox<Orange>();
FruitBox<Apple> bbox = new FruitBox<Apple>();
//Generic Method example
class InstanceType{
int cnt = 0;
InstanceType(){}
public <T>void showType(T inst){
cnt++;
System.out.println(inst);
}
}
InstanceType tmp = new InstanceType();
tmp.showType(aaa);
<T extends AAA> T가 AAA를 상속 또는 구현(AAA가 인터페이스)하는 클래스의 자료형이 되어야함을 명시하며 extends 는 매개변수의 자료형을 제한하는 용도로 사용된다.
FruitBox<? extends Apple> box;
//Apple을 상속하는 모든 클래스
FruitBox<? super Apple> box;
//Apple이 상속된 모든 조상 클래스
##Collection Framework
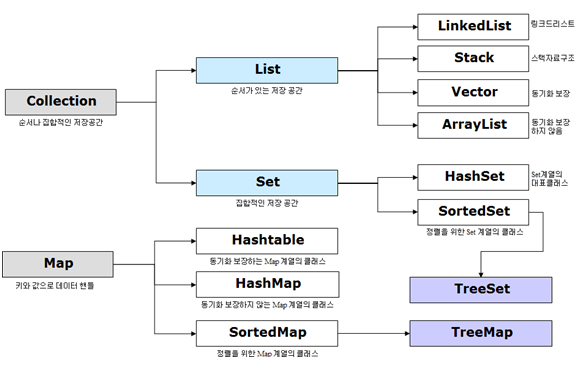
자바의 컬렉션 프레임워크는 인스턴스의 저장과 참조를 위해 별도의 구현과 이해 없이 자료구조와 알고리즘을 적용할 수 있도록 설계된 클래스들의 집합이다.
컬렉션 프레임워크의 인터페이스 구조
###Iterator
자바의 컬렉션 프레임워크에서 컬렉션에 저장되어 있는 요소들을 읽어오는 방법을 표준화 하였는데 그 중 하나가 Iterator 인터페이스이다.
Collection
Iterator에 정의된 메소드
public interface Iterator {
boolean hasNext(); //참조할 다음 번 요소가 존재하면 true 반환
Object next(); //다음번 요소를 반환
void remove(); //현재 위치의 요소 삭제
}
HashSet<Integer> list = new HashSet<Integer>();
list.add(new Integer(22));
list.add(new Integer(12));
list.add(new Integer(2));
Iterator<Integer> itr = list.iterator();
while(itr.hasNext()){
System.out.println(itr.next());
}
###List
순서가 있는 데이터의 집합, 중복 허용 List로 사용할 수 있는 클래스 : ArrayList, LinkedList , Vector
- ArrayList
- 상당히 빠르고 크기를 마음대로 조절할 수 있는 배열
- 단방향 포인터 구조로 자료에 대한 순차적인 접근에 강점이 있음
- LinkedList
- 양방향 포인터 구조로 데이터의 삽입, 삭제가 빈번할 경우 빠른 성능을 보장
- 스택, 큐, 양방향 큐 등을 만들기 위한 용도로 쓰임
- Vector
- ArrayList의 구형 버전. 모든 메소드가 동기화되어 있음, 잘 쓰이진 않음
###Set
순서가 없는 데이터의 집합, 중복 비허용 Set 으로 사용할 수 있는 클래스 : HashSet, LinkedHashSet, TreeSet
- HashSet
- 가장 빠른 임의 접근 속도
- 순서를 전혀 예측할 수 없음
- LinkedHashSet
- 추가된 순서, 또는 가장 최근에 접근한 순서대로 접근 가능
- TreeSet
- 정렬된 순서대로 보관. 정렬 방법을 지정할 수 있음
####HashSet
HashSet
- Object 클래스의 hashCode 메소드의 반환 값을 해시 값으로 활용하여 검색의 그룹을 선택한다.
- 그룹 내의 인스턴스를 대상으로 Object 클래스의 equals 메소드의 반환 값의 결과로 동등을 판단한다.
public int hashCode()
public boolean equals(Object obj)
hashCode 메소드의 구현에 따라서 검색의 성능이 달라지고, 동일 인스턴스를 판단하는 기준에 맞게 equals 메소드를 정의해야 한다.
class SimpleNumber{
int num;
SimpleNumber(int num){
this.num = num;
}
public String toString(){
return String.valueOf(num);
}
public int hashCode(){
return num%3;
}
public boolean equals(Object obj){
SimpleNumber tmp = (SimpleNumber)obj;
if(num == tmp.num){
return true;
} else{
return false;
}
}
}
####TreeSet
- TreeSet
클래스는 트리라는 자료구조를 기반으로 데이터를 저장한다. - 데이터를 정렬된 순서로 저장하며, HashSet
와 마찬가지로 데이터의 중복 저장은 하지 않는다. - 정렬의 기준은 프로그래머가 직접 정의한다.
#####Comparable
- TreeSet
인스턴스에 저장이 되려면 Comparable 인터페이스를 구현해야 한다. - Comparable
인터페이스의 유일한 메소드는 int compareTo(T obj); 이다. compareTo메소드는 다음의 기준으로 구현을 해야한다.- 인자로 전달된 obj가 작다면 양의 정수를 반환해라.
- 인자로 전달된 obj가 크다면 음의정수를 반환해라.
- 인자로 전달된 obj와 같다면 0을 반환해라.
- 작다, 크다, 같다의 기준은 프로그래머가 결정한다.
//Comparable Example
class Person implements Comparable<Person>{
private int age;
private String name;
Person(String name, int age){
this.age = age;
this.name = name;
}
@Override
public int compareTo(Person o) {
return name.compareTo(o.name) ; //알파벳 순 정렬
}
}
public class HashSetOne {
public static void main(String[] args) {
TreeSet<Person> tSet = new TreeSet<Person>();
}
}
*비교에 관한 처리만 필요할 경우 Comparator
//Comparator Example
class MyString implements Comparator<String>{
@Override
public int compare(String o1, String o2) {
return o1.length() - o2.length(); //길이 순 정렬
}
}
public class IntroComparator {
public static void main(String[] args) {
TreeSet<String> itr = new TreeSet<String>(new MyString());
itr.add("ddd");
}
}
###Map
List와 Set이 순서나 집합적인 개념의 인터페이스라면 Map은 검색의 개념이 가미된 인터페이스이다. 키(Key)와 값(Value)으로 이루어진 데이터의 집합, 순서가 없으며 키는 중복을 허용하지 않고 값은 중복을 허용
- Map<K, V> 인터페이스를 구현하는 컬렉션 클래스는 key-value 방식의 데이터 저장을 한다.
- value는 저장할 데이터를 의미하고, key는value를 찾는 열쇠를 의미한다.
- Map<K, V>를 구현하는 대표적인 클래스로는 HashMap<K, V>와 TreeMap<K, V>가 있다.
- TreeMap<K, V>는 정렬된 형태로 데이터가 저장된다.
##Thread와 동기화
프로세스란 실행중인 프로그램을 의미하며 쓰레드는 프로세스 내에서 별도의 실행 흐름을 갖는 대상이다. 쓰레드는 모든 일의 기본 단위로 main 메소드를 호출하는 것도 프로세스 생성 시 함께 생성되는 main 쓰레드 를 통해서 이루어진다.
별도의 쓰레드 생성을 위해서는 Thread 를 상속하는 쓰레드 클래스를 정의해야 한다.
####쓰레드 생성
쓰레드를 생성하는 방법은 2가지가 있으며 다른 클래스를 상속받아 쓰레드를 생성 할때는 Runnable 인터페이스를 구현한다.
- Thread 클래스를 상속
- Thread 클래스를 상속받는 클래스를 작성한다.
- public void run() 메소드를 오버라이딩한다.
- main() 메소드에서 Thread 클래스를 상속하는 클래스의 객체를 생성한다.
- 해당 객체의 start() 메소드를 호출하여 스레드를 실행시킨다.
- Runnable 인터페이스를 구현
- Runnable 인터페이스를 구현하는 클래스를 작성한다.
- public void run() 메소드를 오버라이딩 한다.
- main() 메소드에서 Runnable 인터페이스를 구현하는 클래스의 객체를 생성한다.
- Thread 클래스의 객체를 생성하면서 생성자의 인자로 Runnable 인터페이스를 구현한 클래스의 객체를 전달한다.
- Thread 객체의 start() 메소드를 호출한다.
//Thread 클래스 상속
class ShowThread extends Thread{
String threadName;
ShowThread(String threadName){
this.threadName = threadName;
}
public void run(){
for(int i=0;i<100;i++){
System.out.println(threadName);
try {
sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class IntroThread {
public static void main(String[] args) {
ShowThread st1 = new ShowThread("aa");
ShowThread st2 = new ShowThread("bb");
st1.start();
st2.start();
}
}
//Runnable 인터페이스 구현
class Sum{
int num;
Sum(int num){
this.num = num;
}
public void addNum(int n){
num += n;
}
public int getNum(){
return num;
}
}
class AdderThread extends Sum implements Runnable{
int start, end;
AdderThread(int start, int end){
super(0);
this.start = start;
this.end = end;
}
public void run(){
for(int i=start;i<=end;i++){
addNum(i);
}
}
}
public class RunableThread {
public static void main(String[] args) {
AdderThread at = new AdderThread(1, 50);
Thread t1 = new Thread(at);
t1.start();
try {
t1.join(); //join() 메소드는 쓰레드가 끝날때까지 기다린다.
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(at.getNum());
}
}
####쓰레드의 라이프 싸이클
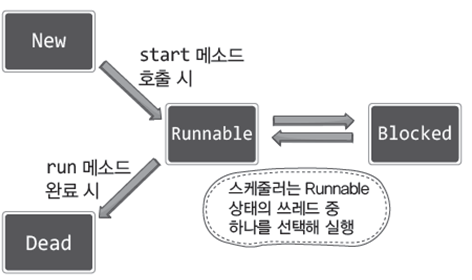
- Runnable 상태의 쓰레드만이 스케줄러에 의해 스케줄링 가능하다.
- 그리고 앞서 보인
sleep,join메소드의 호출로 인해서 쓰레드는 Blocked 상태가 된다. - 한번 종료된 쓰레드는 다시 Runnable 상태가 될 수 없지만, Blocked 상태의 쓰레드는 조건이 성립되면 다시 Runnable 상태가 된다.
####쓰레드의 메모리 구성
- 모든 쓰레드는 스택을 제외한 메소드 영역과 힙을 공유한다. 따라서 이 두 영역을 통해서 데이터를 주고 받을 수 있다.
- 스택은 쓰레드별로 독립적일 수 밖에 없는 이유는, 쓰레드의 실행이 메소드의 호출을 통해서 이뤄지고, 메소드의 호출을 위해서 사용되는 메모리공간이 스택이기 때문이다.
####쓰레드 동기화
쓰레드는 같은 프로세스내에서 동일한 데이터를 공유한다. 따라서 하나의 데이터에 대해서 동시에 여러개의 쓰레드가 접근이 가능하게 되고 그에 따라 데이터의 일관성에 관한 문제가 생길 수가 있다.
그래서 자주 사용되는 것이 synchronized(동기화)이다. 동기화란 하나의 자원(데이터)에 대해서 여러 쓰레드가 사용하려고 할때 한 시점에서 하나의 쓰레드만 사용할 수 있도록 하는 것이다.
synchronized 식별자는 보통 메소드의 선언부에 쓰고 이 키워드가 붙은 메소드는 한번에 하나의 쓰레드만 접근이 가능하며 메소드가 사용중일 때 다른 쓰레드가 메소드를 호출하면 앞의 쓰레드가 종료될때까지 기다려야 한다.
그렇기 때문에 synchronized 메소드의 빈번한 호출은 성능을 크게 감소시키며 적절하게 사용해야 한다.
- 동기화 메소드를 사용하는 방법
- 동기화 블록을 사용하는 방법
//동기화 블록응 사용한 동기화와 그룹화
class Calc{
int opCnt;
int num1, num2;
Calc(){
opCnt = 0;
}
public void addNum1(){
synchronized (this) {
num1++;
}
}
public void subNum1(){
synchronized (this) {
num1--;
}
}
public void addNum2(){
synchronized (key) {
num2++;
}
}
public void subNum2(){
synchronized (key) {
num2--;
}
}
Object key = new Object();
//num1, num2 동기화를 나누어서 진행하기 위해 Object key를 따로 만들어 그룹을 지어준다.
public void showCnt(){
System.out.println("Count: " + opCnt);
}
}
- public final void wait() throws InterruptedException
- 위의 메소드를 호출한 쓰레드는
notify또는notifyAll메소드가 호출될 때까지 블로킹 상태에 놓이게 된다.
- 위의 메소드를 호출한 쓰레드는
- public final void notify()wait
- 메소드의 호출을 통해서 블로킹 상태에 놓여있는 쓰레드 하나를 깨운다.
- public final void notifyAll()wait
- 메소드의 호출을 통해서 블로킹 상태에 놓여있는 모든 쓰레드를 깨운다.
##파일과 I/O 스트림
입출력 대상이 달라지면 프로그램상에서의 입출력 방식도 달라지는 것이 보통이다. 그런데 자바에서는 입출력 대상에 상관없이 입출력의 진행 방식이 동일하도록 별도의 ‘I/O 모델’을 정의하고 있다. I/O 모델의 정의로 인해서 입출력 대상의 차이에 따른 입출력 방식의 차이는 크지않다. 기본적인 입출력의 형태는 동일하다. 그리고 이것이 JAVA의 I/O 스트림이 갖는 장점이다. 데이터의 입력을 위해서는 입력 스트림을, 출력을 위해서는 출력 스트림을 형성해야 하며, 스트림은 자바에서 사용 가능한 연속된 데이터 흐름을 의미한다.
자바 I/O에서 처리 가능한 데이터의 종류는 2가지가 있다.
- byte - byte 처리가 가능하며 이미지 파일 등과 같은 바이너리 위주의 데이터를 입출력할 때 사용한다. 최상위 클래스는
InputStream,OutputStream - char - char 처리가 가능하며 텍스트 위주의 데이터를 입출력할 때 사용한다. 최상위 클래스는 ‘Reader’ ,
Writer
클래스의 객체를 사용 후에는 close() 메소드를 사용하여 자원을 해제해야 한다.
//byte 단위 파일 복사
public static void main(String[] args) throws IOException {
InputStream in = new FileInputStream("aa.txt");
OutputStream out = new FileOutputStream("cc.txt");
int bData;
int copyByte=0;
byte[] buf = new byte[1024]; //한번에 1024byte씩 읽어온다
while(true){
bData = in.read(buf);
if(bData == -1) break;
out.write(buf, 0, bData);
copyByte++;
}
in.close();
out.close();
System.out.println(copyByte);
}
//필터 스트림 활용
//파일에 double형 데이터 저장 + 버퍼링
public static void performanceTest(DataOutputStream data) throws IOException{
long startTime = System.currentTimeMillis();
for(int i=0; i<1000000; i++){
data.writeDouble(3.14);
}
data.flush(); //데이터 강제 전송
long endTime = System.currentTimeMillis();
System.out.println("수행시간: "+(endTime - startTime));
}
public static void main(String[] args) throws IOException {
DataOutputStream out = new DataOutputStream(new FileOutputStream("data.txt"));
performanceTest(out);
out.close();
DataOutputStream out2 = new DataOutputStream(new BufferedOutputStream(new FileOutputStream("data.txt")));
performanceTest(out2);
out.close();
//BufferedOutputStream 의 시간이 훨씬 짧다.
//BufferdStream을 항상 사용하자!!
}
###문자스트림
바이트 스트림은 데이터를 있는 그대로 송수신하는 스트림이다. 그리고 이 바이트 스트림을 이용하여 문자를 파일에 저장하는 것도 가능하다. 물론 이렇게 저장된 데이터를 자바프로그램을 이용해서 읽으면 문제되지 않는다. 하지만 다른 프로그램을 이용해서 읽으면 문제가 될 수 있다. BufferedReader 를 반드시 사용하자
BufferedWriter bw = new BufferedWriter(new FileWriter("String.txt"));
BufferedReader br = new BufferedReader(new FileReader("String.txt"));
###직렬화()
객체의 직렬화는 객체의 내용을 바이트 단위로 변환하여 파일 또는 네트워크를 통해서 스트림(송수신)이 가능하게 하는것을 의미한다.
자바 I/O 처리는 정수, 문자열, 바이트 단위의 처리만 지원했었다.따라서 복잡한 객체의 내용을 저장/복원하거나, 네트워크로 전송하기 위해서는 객체의 멤버변수의 각 내용을 일정한 형식으로 만들어(이것을 패킷이라고 한다) 전송해야 했다. 객체직렬화는 객체의 내용(구체적으로는 멤버변수의 내용, 생성자나 메소드는 제외)을 자바 I/O가 자동적으로 바이트 단위로 변환하여, 저장/복원하거나 네트워크로 전송할 수 있도록 기능을 제공해준다. 즉, 개발자 입장에서는 객체가 아무리 복잡하더라도, 객체직렬화를 이용하면 객체의 내용을 자바 I/O가 자동으로 바이트 단위로 변환하여 저장이나 전송을 해주게 된다. 또한 이것은 자바에서 자동으로 처리해주는 것이기 때문에, 운영체제가 달라도 전혀 문제되지 않는다. 객체를 직렬화할때 객체의 멤버변수가 다른 객체(Serializable 인터페이스를 구현한)의 레퍼런스 변수인 경우에는 레퍼런스 변수가 가리키는 해당 객체까지도 같이 객체직렬화를 해버린다. 또 그 객체가 다른 객체를 다시 가리키고 있다면, 같은 식으로 객체직렬화가 계속해서 일어나게 된다.이것은 마치 객체직렬화를 처음 시작한 객체를 중심으로 트리 구조의 객체직렬화가 연속적으로 일어나는 것이다. 직렬화를 통해 객제 내용을 입출력형식에 구해받지 않고 객체를 파일에 저장함으로써 영속성을 제공하게 되며, 객체를 네트워크를 통해 손쉽게 교환이 가능하다.
직렬화의 대상이 되는 인스턴스의 클래스는 java.io.Serializable 인터페이스를 구현해야 한다. 이 인터페이스는 직렬화의 대상임을 표시 하는 인터페이스일뿐, 실제 구현해야 할 메소드가 존재하는 인터페이스는 아니다. 인스턴스가 파일에 저장되는 과정(저장을 위해 거치는 과정)을 가리켜 직렬화(serialization) 라고 하고, 그 반대의 과정을 가리켜 역직렬화(deserialization) 라고 한다.
객체 직렬화를 하기 위해서 먼저 객체를 객체직렬화가 가능하도록 Serializable 인터페이스를 구현해야 한다.그리고 ObjectInputStream 클래스와 ObjectOutputStream 클래스는 객체를 입출력을 하기 위해 사용되는 클래스로 java.io에 정의 되어 있다.
//ObjectOutputStream 클래스의 메소드: 인스턴스 저장
public final void writeObject(Object obj) Throws IOException
//ObjectInputStream 클래스의 메소드: 인스턴스 복원
public final Object readObject() Throws IOException, ClassNotFoundException
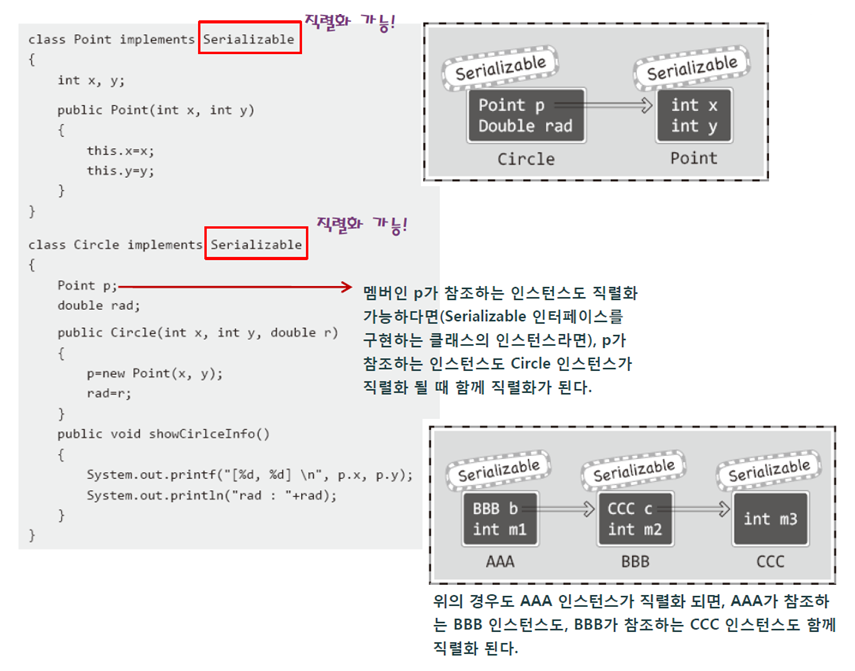
//직렬화와 역직렬화
class Point implements Serializable{
int x, y;
Point(int x, int y){
this.x = x;
this.y = y;
}
}
class Circle implements Serializable{
Point p;
double rad;
Circle(int x, int y, double r){
p = new Point(x, y);
rad = r;
}
public void showCircleInfo(){
System.out.println("[x: "+p.x+", y: "+p.y+"]");
System.out.println("rad: "+rad);
}
}
public class SerializationTest {
public static void main(String[] args) throws FileNotFoundException, IOException, ClassNotFoundException {
Circle c1 = new Circle(1, 1, 2.4);
Circle c2 = new Circle(2, 2, 4.8);
ObjectOutputStream out =
new ObjectOutputStream(new FileOutputStream("CircleInstance.serializable"));
// 직렬화
out.writeObject(c1);
out.writeObject(c2);
out.writeObject(new String("String implements Serializable"));
out.close();
ObjectInputStream in =
new ObjectInputStream(new FileInputStream("CircleInstance.serializable"));
// 역직렬화
Circle c3 = (Circle)in.readObject();
Circle c4 = (Circle)in.readObject();
String mess = (String)in.readObject();
in.close();
c3.showCircleInfo();
c4.showCircleInfo();
System.out.println(mess);
}
}
transient 로 선언된 멤버는 직렬화의 대상에서 제외된다.